Ejercicio 1: Preparar la base de datos de Analysis Services
Crear un proyecto de Analysis Services
Cada proyecto de Microsoft SQL Server 2008 Analysis Services (SSAS) define el esquema para los objetos de una base de datos de Analysis Services individual. La base de datos de Analysis Services está definida por los modelos de minería de datos, los cubos OLAP y los objetos complementarios que contiene.
Crear un origen de datos
Un origen de datos es una conexión de datos que se guarda y administra en el proyecto y se implementa en la base de datos Microsoft SQL Server 2008 Analysis Services (SSAS). El origen de datos contiene el nombre del servidor y la base de datos donde residen los datos del origen, además de otras propiedades de conexión necesarias.
Crear una vista de origen de datos
Una vista de origen de datos ofrece una abstracción del origen de datos. Esto le permite modificar la estructura de los datos para que sean más significativos en el contexto del proyecto. Mediante el uso de vistas de origen de datos, puede seleccionar las tablas relacionadas con un proyecto concreto, establecer relaciones entre ellas e incorporar columnas calculadas y vistas con nombre sin modificar el origen de datos original.
1. En la página de inicio del Asistente para vistas de origen de datos, haga clic en Siguiente.
2. En la página Seleccionar un origen de datos, el origen de datos Adventure Works DW que se creó en la última tarea aparecerá seleccionado de forma predeterminada en Orígenes de datos relacionales. Haga clic en Siguiente.
Cada proyecto de Microsoft SQL Server 2008 Analysis Services (SSAS) define el esquema para los objetos de una base de datos de Analysis Services individual. La base de datos de Analysis Services está definida por los modelos de minería de datos, los cubos OLAP y los objetos complementarios que contiene.
Crear un origen de datos
Un origen de datos es una conexión de datos que se guarda y administra en el proyecto y se implementa en la base de datos Microsoft SQL Server 2008 Analysis Services (SSAS). El origen de datos contiene el nombre del servidor y la base de datos donde residen los datos del origen, además de otras propiedades de conexión necesarias.
Crear una vista de origen de datos
Una vista de origen de datos ofrece una abstracción del origen de datos. Esto le permite modificar la estructura de los datos para que sean más significativos en el contexto del proyecto. Mediante el uso de vistas de origen de datos, puede seleccionar las tablas relacionadas con un proyecto concreto, establecer relaciones entre ellas e incorporar columnas calculadas y vistas con nombre sin modificar el origen de datos original.
1. En la página de inicio del Asistente para vistas de origen de datos, haga clic en Siguiente.
2. En la página Seleccionar un origen de datos, el origen de datos Adventure Works DW que se creó en la última tarea aparecerá seleccionado de forma predeterminada en Orígenes de datos relacionales. Haga clic en Siguiente.

3. En la página Seleccionar tablas y vistas, seleccione las tablas siguientes y, a continuación, haga clic en la flecha derecha para incluirlas en la nueva vista de origen de datos:
- dbo.ProspectiveBuyer
- dbo.vAssocSeqLineItems
- dbo.vAssocSeqOrders
- dbo.vTargetMail
- dbo.vTimeSeries

5. Haga clic en Siguiente.
6. En la página Finalizando el asistente, la vista de origen de datos tendrá el nombre Adventure Works DW de forma predeterminada. Haga clic en Finalizar.
Modificar una vista de origen de datos
Puede utilizar el Diseñador de vistas de origen de datos para cambiar la forma de ver los datos en un origen de datos.
Así, por ejemplo, puede cambiar el nombre de cualquier objeto por uno que sea más significativo para el proyecto. El nombre del objeto no se modifica en el origen de datos original, pero puede referirse al objeto dentro del proyecto utilizando este nombre más descriptivo.
Para crear una cesta de mercado y escenarios de clústeres de secuencia, tiene que crear una nueva relación de varios a uno entre las tablas vAssocSeqOrders y vAssocSeqLineItems.
Mediante esta relación, puede convertir vAssocSeqLineItems en una tabla anidada de vAssocSeqOrders para crear modelos.
Para crear una nueva relación entre tablas:
1. En el panel de la vista de origen de datos del Diseñador de vistas de origen de datos, seleccione la columna OrderNumber de la tabla vAssocSeqLineItems.
2. Arrastre la columna hasta la tabla vAssocSeqOrders y colóquela en la columna
OrderNumber. Ahora existirá una nueva relación de varios a uno entre las tablas vAssocSeqOrders y vAssocSeqLineItems.

Mediante esta relación, puede convertir vAssocSeqLineItems en una tabla anidada de vAssocSeqOrders para crear modelos.
Para crear una nueva relación entre tablas:
1. En el panel de la vista de origen de datos del Diseñador de vistas de origen de datos, seleccione la columna OrderNumber de la tabla vAssocSeqLineItems.
2. Arrastre la columna hasta la tabla vAssocSeqOrders y colóquela en la columna
OrderNumber. Ahora existirá una nueva relación de varios a uno entre las tablas vAssocSeqOrders y vAssocSeqLineItems.

Ejercicio 2: Crear un escenario de correo directo
El departamento de marketing de Adventure Works desea aumentar las ventas dirigiendo una campaña de correo directo a clientes específicos. Mediante el análisis de los atributos de clientes conocidos, la empresa espera determinar los patrones que posteriormente se aplicarán a clientes potenciales. La empresa pretende utilizar los patrones hallados para predecir qué clientes potenciales tienen más probabilidades de comprar un producto.
Además, el departamento de marketing desea encontrar las posibles agrupaciones lógicas de clientes que se encuentran en la base de datos, como, por ejemplo, aquellos que siguen pautas demográficas y de compra similares. La base de datos de la empresa, Adventure Works DW, contiene una lista de clientes antiguos y una lista de clientes nuevos potenciales.
Crear una estructura del modelo de minería de datos Targeted Mailing
El primer paso para crear un escenario de correo directo (Targeted Mailing) consiste en utilizar el Asistente para minería de datos de Business Intelligence Development Studio con el fin de crear una estructura de minería de datos y un modelo de minería de datos de árbol de decisión.
Para crear una estructura de minería de datos para un escenario de correo directo:
1. En el Explorador de soluciones, haga clic con el botón secundario en Estructuras
de minería de datos y seleccione Nueva estructura de minería de datos.
Se abrirá el Asistente para minería de datos.
2. En la página de inicio del Asistente para minería de datos, haga clic en Siguiente.
3. En la página Seleccionar el método de definición, compruebe que la opción A
partir de una base de datos relacional o un almacén de datos se ha seleccionado
y, a continuación, haga clic en Siguiente.
4. En la página Seleccionar la técnica de minería de datos, en ¿Qué técnica de minería de datos desea utilizar?, seleccione Árboles de decisión de Microsoft.
Crear una estructura del modelo de minería de datos Targeted Mailing
El primer paso para crear un escenario de correo directo (Targeted Mailing) consiste en utilizar el Asistente para minería de datos de Business Intelligence Development Studio con el fin de crear una estructura de minería de datos y un modelo de minería de datos de árbol de decisión.
Para crear una estructura de minería de datos para un escenario de correo directo:
1. En el Explorador de soluciones, haga clic con el botón secundario en Estructuras
de minería de datos y seleccione Nueva estructura de minería de datos.
Se abrirá el Asistente para minería de datos.
2. En la página de inicio del Asistente para minería de datos, haga clic en Siguiente.
3. En la página Seleccionar el método de definición, compruebe que la opción A
partir de una base de datos relacional o un almacén de datos se ha seleccionado
y, a continuación, haga clic en Siguiente.
4. En la página Seleccionar la técnica de minería de datos, en ¿Qué técnica de minería de datos desea utilizar?, seleccione Árboles de decisión de Microsoft.

5. Haga clic en Siguiente.
6. En la página Seleccionar vista de origen de datos, observe que Adventure Works DW se ha seleccionado de forma predeterminada. Haga clic en Explorar para ver las tablas de la vista de origen de datos y, a continuación, haga clic en Cerrar para volver al asistente.
6. En la página Seleccionar vista de origen de datos, observe que Adventure Works DW se ha seleccionado de forma predeterminada. Haga clic en Explorar para ver las tablas de la vista de origen de datos y, a continuación, haga clic en Cerrar para volver al asistente.

7. Haga clic en Siguiente.
8. En la página Especificar tipos de tablas, active la casilla de verificación de la columna Escenario, situada junto a la tabla vTargetMail; a continuación, haga clic en Siguiente.

9. En la página Especificar los datos de entrenamiento, compruebe que la casilla de verificación de la columna Clave junto a la columna CustomerKey está activada. Si la tabla de origen de la vista de origen de datos muestra una clave, el Asistente para minería de datos elegirá automáticamente esa columna como clave para el modelo.
10. Active las casillas de verificación Entrada y De predicción, situadas junto a la columna BikeBuyer. Al indicar que una columna es de predicción, se habilita el botón Sugerir. Si hace clic en Sugerir, se abrirá el cuadro de diálogo Sugerir columnas relacionadas, que enumera las columnas que están más ligadas a la columna de predicción.
El cuadro de diálogo Sugerir columnas relacionadas ordena los atributos según la relación que tengan con el atributo de predicción. Las columnas cuyo valor es mayor que 0,05 se seleccionan automáticamente para ser incluidas en el modelo. Si las sugerencias le parecen bien, haga clic en Aceptar para que las columnas seleccionadas se marquen como columnas de entrada en el asistente. Para este ejercicio, omita las sugerencias haciendo clic en Cancelar.
11.Active las casillas de verificación Entrada que hay junto a las columnas siguientes:
- Age
- CommuteDistance
- SpanishEducation
- SpanihOccupation
- FirstName
- Gender
- GeographyKey
- HouseOwnerFlag
- LastName
- MaritalStatus
- NumberCarsOwned
- NumberChildrenAtHome
- Region
- TotalChildren
- YearlyIncome
Puede seleccionar varias columnas si mantiene presionada la tecla MAYÚS.
- Age
- CommuteDistance
- SpanishEducation
- SpanihOccupation
- FirstName
- Gender
- GeographyKey
- HouseOwnerFlag
- LastName
- MaritalStatus
- NumberCarsOwned
- NumberChildrenAtHome
- Region
- TotalChildren
- YearlyIncome
Puede seleccionar varias columnas si mantiene presionada la tecla MAYÚS.
12. Haga clic en Siguiente.
13. En la página Especificar el contenido y el tipo de datos de las columnas, haga clic en Detectar.
Un algoritmo ejecutará los datos numéricos de los ejemplos y determinará si las columnas numéricas contienen valores continuos o discretos. Por ejemplo, una columna puede contener información salarial como valores de sueldo actuales, que son continuos, o bien integrales que representan rangos de sueldo codificados, como 1 = < $25.000; 2 = de $25.000 a $50.000, que son discretos.
13. En la página Especificar el contenido y el tipo de datos de las columnas, haga clic en Detectar.
Un algoritmo ejecutará los datos numéricos de los ejemplos y determinará si las columnas numéricas contienen valores continuos o discretos. Por ejemplo, una columna puede contener información salarial como valores de sueldo actuales, que son continuos, o bien integrales que representan rangos de sueldo codificados, como 1 = < $25.000; 2 = de $25.000 a $50.000, que son discretos.
14. Después de hacer clic en Detectar, compruebe que las entradas de las columnas Tipo de contenido y Tipo de datos tengan la configuración especificada en la siguiente tabla.
Columna | Tipo de Contenido | Tipo de Datos |
Age | Continuous | Long |
BikeBuyer | Discrete | Long |
CommuteDistance | Discrete | Text |
CustomerKey | Key | Long |
EnglishEducation | Discrete | Text |
EnglishOccupation | Discrete | Text |
FirstName | Discrete | Text |
Gender | Discrete | Text |
GeographyKey | Discrete | Text |
HouseOwnerFlag | Discrete | Text |
LastName | Discrete | Text |
MaritalStatus | Discrete | Text |
NumberCarsOwned | Discrete | Long |
NumberChildrenAtHome | Discrete | Long |
Region | Discrete | Text |
TotalChildren | Discrete | Long |
YearlyIncome | Continuous | Double |
Nota: Basándose únicamente en los valores numéricos, el algoritmo de minería de datos sugiere que la columna GeographyKey contiene números continuos. Sin embargo, algunos números como los códigos postales deben tratarse normalmente como discretos y no como valores numéricos continuos, ya que las operaciones matemáticas que usan estos números carecen de significado.
Haga clic en Siguiente.
En la página Finalización del asistente, en Nombre de la estructura de minería de datos, escriba Targeted Mailing.
En Nombre del modelo de minería de datos, escriba TM_Decision_Tree.
Active la casilla de verificación Permitir obtención de detalles. Haga clic en Finalizar.

En la página Finalización del asistente, en Nombre de la estructura de minería de datos, escriba Targeted Mailing.
En Nombre del modelo de minería de datos, escriba TM_Decision_Tree.
Active la casilla de verificación Permitir obtención de detalles. Haga clic en Finalizar.

Ejercicio 3 - Modificar el modelo Targeted Mailing
La estructura de minería de datos que creó en la tarea anterior contiene un modelo de minería de datos individual que se basa en el algoritmo de árboles de decisión de Microsoft. En esta tarea, definirá dos modelos adicionales mediante la ficha Modelos de minería de datos del Diseñador de minería de datos. En esta tarea, definirá un modelo Naive Bayes y un modelo Clustering.
La estructura de minería de datos que creó en la tarea anterior contiene un modelo de minería de datos individual que se basa en el algoritmo de árboles de decisión de Microsoft. En esta tarea, definirá dos modelos adicionales mediante la ficha Modelos de minería de datos del Diseñador de minería de datos. En esta tarea, definirá un modelo Naive Bayes y un modelo Clustering.
Crear un modelo Microsoft Clustering
Para crear un modelo de minería de datos de clúster:
1. Cambie a la ficha Modelos de minería de datos del Diseñador de minería de datos en Business Intelligence Development Studio. Observe que el diseñador muestra dos columnas: una para la estructura de minería de datos y otra para el modelo de minería de datos inicial, que creó en la tarea anterior de este ejercicio.
2. Haga clic con el botón secundario en la columna Estructura y seleccione Nuevo modelo de minería de datos.
Se abrirá el cuadro de diálogo Nuevo modelo de minería de datos.
3. En Nombre del modelo, escriba TM_Clustering.
4. En Nombre del algoritmo, seleccione Clústeres de Microsoft.
5. Haga clic en Aceptar.

Aparece un modelo nuevo en la ficha Modelos de minería de datos del Diseñador de minería de datos. Un modelo creado con el algoritmo de clústeres de Microsoft puede agrupar en clúster y predecir atributos continuos y discretos. Aunque puede modificar el uso y las propiedades de la columna para el modelo nuevo, en este ejercicio no es necesario hacer cambios en el modelo TM_Clustering.
Crear un modelo Microsoft Naive Bayes
Para crear un modelo Bayes naive:
1. En la ficha Modelos de minería de datos del Diseñador de minería de datos, haga clic con el botón secundario en la columna Estructura y seleccione Nuevo modelo de minería de datos. Se abrirá el cuadro de diálogo Nuevo modelo de minería de datos.
Para crear un modelo Bayes naive:
1. En la ficha Modelos de minería de datos del Diseñador de minería de datos, haga clic con el botón secundario en la columna Estructura y seleccione Nuevo modelo de minería de datos. Se abrirá el cuadro de diálogo Nuevo modelo de minería de datos.
2. En Nombre del modelo, escriba TM_NaiveBayes. =
3. En Nombre del algoritmo, seleccione Bayes naive de Microsoft. Haga clic en Aceptar. Aparece un mensaje explicando que el algoritmo Bayes naive de Microsoft no admite columnas continuas. Para trabajar con estas columnas en el modelo Bayes naive, debe discretizarlas. En este ejercicio, se omitirán las columnas.
4. Haga clic en Sí para confirmar el mensaje y continuar.
Aparece un modelo nuevo en la ficha Modelos de minería de datos. Aunque puede modificar el uso y las propiedades de la columna para todos los modelos de la ficha, en este ejercicio, no es necesario hacer cambios en el modelo TM_NaiveBayes.

3. En Nombre del algoritmo, seleccione Bayes naive de Microsoft. Haga clic en Aceptar. Aparece un mensaje explicando que el algoritmo Bayes naive de Microsoft no admite columnas continuas. Para trabajar con estas columnas en el modelo Bayes naive, debe discretizarlas. En este ejercicio, se omitirán las columnas.
4. Haga clic en Sí para confirmar el mensaje y continuar.
Aparece un modelo nuevo en la ficha Modelos de minería de datos. Aunque puede modificar el uso y las propiedades de la columna para todos los modelos de la ficha, en este ejercicio, no es necesario hacer cambios en el modelo TM_NaiveBayes.

Procesar los modelos de minería de datos
Ahora que la estructura y los parámetros para los modelos de minería de datos se han completado, puede implementar y procesar los modelos.
Para implementar el proyecto y procesar los modelos de minería de datos:
En el menú Depurar, seleccione Iniciar depuración. O, puede presionar F5. La base de datos Analysis Services se implementa en el equipo servidor y los modelos de minería de datos se procesan.
Ejercicio 4 - Explorar los modelos Targeted Mailing
Una vez que se procesen los modelos de su proyecto, podrá verlos utilizando la ficha Visor de modelos de minería de datos del Diseñador de minería de datos. Puede utilizar la lista Modelos de minería de datos, ubicada en la parte superior de la ficha, para examinar los modelos individuales en la estructura de minería de datos.
Las secciones siguientes describen cómo explorar los modelos de minería de datos en los visores.
- Modelo Microsoft Decision Tree
- Modelo Microsoft Clustering
- Modelo Microsoft Naive Bayes
Modelo Microsoft Decision Tree
Las secciones siguientes describen cómo explorar los modelos de minería de datos en los visores.
- Modelo Microsoft Decision Tree
- Modelo Microsoft Clustering
- Modelo Microsoft Naive Bayes
Modelo Microsoft Decision Tree
Cuando cambie a la ficha Visor de modelos de minería de datos en el Diseñador de minería de datos para el proyecto del ejercicio Adventure Works DM, el diseñador se abre con el modelo de minería de datos de correo directo (Targeted Mailing), que es el primero de la estructura. Cada algoritmo utilizado para crear un modelo en Analysis Services aporta diferentes resultados. Por tanto, Analysis Services ofrece un visor independiente para cada algoritmo. Cuando se examina un modelo de minería de datos, el modelo se muestra en la ficha Visor de modelos de minería de datos utilizando el visor apropiado para el modelo.
En este caso, para el modelo de árbol de decisión, se utiliza el Visor de árboles de Microsoft. Este visor contiene dos fichas: Árbol de decisión y Red de dependencias.
Árbol de decisión
En la ficha Árbol de decisión, puede examinar los tres modelos de árbol que componen un modelo de minería de datos. Dado que el modelo de correo directo incluido en este proyecto de ejercicio contiene un único atributo de predicción (Bike Buyer), sólo hay un árbol para ver. Si hubiera más árboles, podría utilizar el cuadro Árbol para elegir uno diferente.
De manera predeterminada, el Visor de árboles de Microsoft sólo muestra los primeros tres niveles del árbol. Si el árbol contiene menos de tres niveles, el visor mostrará sólo los niveles existentes. Puede ver más niveles utilizando el control deslizante Mostrar nivel o la lista Expansión predeterminada..
Para modificar el árbol
Para modificar el árbol
1. Deslice Mostrar nivel hasta 5.
2. Cambie la lista Fondo a 1.
Al cambiar la configuración de Fondo, podrá ver rápidamente el número de escenarios para Bike Buyer que son igual a 1 y que existen en cada nodo. Cuanto más oscuro sea el sombreado del nodo, más escenarios incluirá. Cada nodo del árbol de decisión muestra la siguiente información:
- La condición necesaria para alcanzar el nodo desde el nodo anterior. Puede ver la ruta completa del nodo en la Leyenda de minería de datos o deteniendo el puntero sobre un nodo para ver un recuadro informativo.
- Un histograma que describe la distribución de estados de la columna de predicción
por orden de popularidad. Puede decidir cuántos estados aparecerán en el
histograma mediante el control Histogramas.
- La concentración de escenarios, si el estado del atributo de predicción se ha
especificado en el control Fondo.
Puede ver los escenarios de entrenamiento que cada nodo admite haciendo clic con el botón secundario en el nodo y, a continuación, seleccionando Obtener detalles.

2. Cambie la lista Fondo a 1.
Al cambiar la configuración de Fondo, podrá ver rápidamente el número de escenarios para Bike Buyer que son igual a 1 y que existen en cada nodo. Cuanto más oscuro sea el sombreado del nodo, más escenarios incluirá. Cada nodo del árbol de decisión muestra la siguiente información:
- La condición necesaria para alcanzar el nodo desde el nodo anterior. Puede ver la ruta completa del nodo en la Leyenda de minería de datos o deteniendo el puntero sobre un nodo para ver un recuadro informativo.
- Un histograma que describe la distribución de estados de la columna de predicción
por orden de popularidad. Puede decidir cuántos estados aparecerán en el
histograma mediante el control Histogramas.
- La concentración de escenarios, si el estado del atributo de predicción se ha
especificado en el control Fondo.
Puede ver los escenarios de entrenamiento que cada nodo admite haciendo clic con el botón secundario en el nodo y, a continuación, seleccionando Obtener detalles.

Red de dependencias
La ficha Red de dependencias muestra las relaciones entre los atributos que contribuyen a la capacidad de predicción del modelo de minería de datos.
El nodo central para la red de dependencia, Bike Buyer, representa el atributo de predicción del modelo de minería de datos. Cada nodo adyacente representa un atributo que afecta al resultado del atributo de predicción. Puede utilizar el control deslizante situado en la parte izquierda de la ficha para controlar la intensidad de los vínculos que se muestran. Si desplaza el control deslizante hacia abajo, sólo se mostrarán los vínculos de mayor intensidad.
Haga clic en un nodo de la red y, a continuación, consulte la leyenda de color situada en la parte inferior de la ficha para ver cuáles son los nodos predichos por el nodo seleccionado o los nodos que predicen al nodo seleccionado.



Modelo Microsoft Clustering
Utilice la lista Modelo de minería de datos de la parte superior de la ficha Visor de modelos de minería de datos para cambiar al modelo TM_Clustering. El visor de este modelo, el Visor de clústeres de Microsoft, contiene cuatro fichas: Diagrama del clúster, Perfiles del clúster, Características del clúster y Distinción del clúster. De forma predeterminada, el visor muestra la ficha Diagrama del clúster cuando se abre por primera vez.
Diagrama del clúster
La ficha Diagrama del clúster permite explorar las relaciones entre los clústeres
detectados por el algoritmo. Las líneas entre los clústeres representan la "proximidad" y aparecen sombreadas en función de la similitud entre los clústeres. El color de cada clúster representa la frecuencia de la variable y el estado del clúster. Puede seleccionar la variable y el estado en los cuadros Variable de sombreado y Estado de la parte superior del nodo.
La variable predeterminada es Llenado, pero puede cambiarla a cualquier atributo del
modelo con el fin de determinar los clústeres que contienen miembros con los atributos que desea. Si utiliza el control deslizante situado en la parte izquierda de la red, puede filtrar los vínculos de menor intensidad y encontrar los clústeres con las relaciones más próximas.
Por ejemplo, establezca Variable de sombreado en Bike Buyer y Estado en 1. Observará
que el clúster 5 es el que contiene la mayor densidad de compradores de bicicleta (Bike Buyer) y que la relación más fuerte existe entre el clúster 4 y el clúster 7.
Utilice la lista Modelo de minería de datos de la parte superior de la ficha Visor de modelos de minería de datos para cambiar al modelo TM_Clustering. El visor de este modelo, el Visor de clústeres de Microsoft, contiene cuatro fichas: Diagrama del clúster, Perfiles del clúster, Características del clúster y Distinción del clúster. De forma predeterminada, el visor muestra la ficha Diagrama del clúster cuando se abre por primera vez.
Diagrama del clúster
La ficha Diagrama del clúster permite explorar las relaciones entre los clústeres
detectados por el algoritmo. Las líneas entre los clústeres representan la "proximidad" y aparecen sombreadas en función de la similitud entre los clústeres. El color de cada clúster representa la frecuencia de la variable y el estado del clúster. Puede seleccionar la variable y el estado en los cuadros Variable de sombreado y Estado de la parte superior del nodo.
La variable predeterminada es Llenado, pero puede cambiarla a cualquier atributo del
modelo con el fin de determinar los clústeres que contienen miembros con los atributos que desea. Si utiliza el control deslizante situado en la parte izquierda de la red, puede filtrar los vínculos de menor intensidad y encontrar los clústeres con las relaciones más próximas.
Por ejemplo, establezca Variable de sombreado en Bike Buyer y Estado en 1. Observará
que el clúster 5 es el que contiene la mayor densidad de compradores de bicicleta (Bike Buyer) y que la relación más fuerte existe entre el clúster 4 y el clúster 7.

Perfiles del clúster
La ficha Perfiles del clúster proporciona una vista global del modelo TM_Clustering.
Como podrá ver en el visor, la ficha Perfiles del clúster contiene una columna por cada clúster del modelo. La primera columna enumera los atributos asociados a un clúster como mínimo. El resto del visor contiene la distribución de estados de un atributo por cada clúster. La distribución de una variable discreta se muestra como una barra coloreada y el número máximo de barras aparece en la lista Barras de histograma. Los atributos continuos se muestran con un diagrama de rombo, que representa la desviación media y estándar en cada clúster.

La ficha Perfiles del clúster proporciona una vista global del modelo TM_Clustering.
Como podrá ver en el visor, la ficha Perfiles del clúster contiene una columna por cada clúster del modelo. La primera columna enumera los atributos asociados a un clúster como mínimo. El resto del visor contiene la distribución de estados de un atributo por cada clúster. La distribución de una variable discreta se muestra como una barra coloreada y el número máximo de barras aparece en la lista Barras de histograma. Los atributos continuos se muestran con un diagrama de rombo, que representa la desviación media y estándar en cada clúster.

Características del clúster
La ficha Características del clúster le permite examinar con más detalle las características que forman un clúster. Por ejemplo, si utiliza la lista Clúster para mostrar el clúster 5 en el escenario de este ejercicio, podrá ver que las personas de este clúster, que son clientes que han comprado una bicicleta en el pasado, tienden a compartir las mismas características: viajan todos los días entre 0 y 1 millas, no tienen coche y están casados.

Distinción del clúster
La ficha Distinción del clúster le permite explorar las características que diferencian a un clúster de otro. Después de seleccionar dos clústeres de los cuadros Clúster 1 y Clúster 2, el visor determinará las diferencias entre los clústeres y las mostrará según el orden de los atributos que más distinguen a los clústeres. Por ejemplo, compare el clúster 5 y el clúster 7 del modelo TM_Clustering. El clúster 5 contiene la mayor densidad de compradores de bicicleta y el clúster 7 contiene la menor densidad. Las personas del clúster 7 son normalmente de Norteamérica y son más jóvenes, entre 23 y 31 años, mientras que las personas del clúster 5 suelen ser de Europa y recorren una distancia menor, entre 0 y 1 millas.

Modelo Microsoft Naive Bayes
Utilice la lista Modelo de minería de datos de la parte superior de la ficha Visor de modelos de minería de datos para cambiar al modelo TM_NaiveBayes. El visor de este modelo, el Visor Bayes naive de Microsoft, contiene cuatro fichas: Red de dependencias, Perfiles del atributo, Características del atributo y Distinción del atributo.
Red de dependencias
La ficha Red de dependencias funciona igual que la ficha del mismo nombre del Visor de árboles de Microsoft. Cada nodo del visor representa un atributo y las líneas entre los nodos representan relaciones. En el visor, puede ver todos los atributos que afectan al estado del atributo de predicción, Bike Buyer. A medida que baje el control deslizante, sólo permanecerán los atributos que afecten en mayor medida a la columna Bike Buyer. Al ajustar el control deslizante, puede ver que el número de coches en propiedad es el factor que más determina si alguien es un comprador de bicicleta.
La ficha Red de dependencias funciona igual que la ficha del mismo nombre del Visor de árboles de Microsoft. Cada nodo del visor representa un atributo y las líneas entre los nodos representan relaciones. En el visor, puede ver todos los atributos que afectan al estado del atributo de predicción, Bike Buyer. A medida que baje el control deslizante, sólo permanecerán los atributos que afecten en mayor medida a la columna Bike Buyer. Al ajustar el control deslizante, puede ver que el número de coches en propiedad es el factor que más determina si alguien es un comprador de bicicleta.

Perfiles del atributo
La ficha Perfiles del atributo describe la forma en que los diferentes estados de los atributos de entrada afectan al resultado del atributo de predicción.
En el cuadro De predicción, compruebe que se ha seleccionado Bike Buyer. Los atributos que afectan al estado de este atributo de predicción aparecen enumerados junto a los valores de cada estado de los atributos de entrada y sus distribuciones en cada estado del atributo de predicción.

Características del atributo
Mediante la ficha Características del atributo, puede seleccionar un atributo y un valor para ver la frecuencia con la que aparecen los valores de otros atributos en el caso de los valores seleccionados.
En la lista Atributo, compruebe que Bike Buyer se haya seleccionado, y en la lista Valor, seleccione 1. En el visor, podrá ver que las personas que viajan todos los días entre 0 y 1 millas para trabajar y que viven en Norteamérica son los que compran más bicicletas.

Distinción del atributo
La ficha Distinción del atributo le permite examinar las relaciones entre dos valores discretos del atributo de predicción seleccionado y otros valores del atributo. Dado que el modelo TM_NaiveBayes sólo tiene dos estados, 1 y 0, no tiene que hacer ningún cambio en el visor.
En el visor, podrá ver que las personas que no tienen un coche tienden a comprar bicicletas y las personas que tienen dos coches no suelen comprar bicicletas.

Ejercicio 5 - Crear predicciones
Una vez que haya probado la precisión de los modelos de minería de datos y esté satisfecho con los resultados, puede crear consultas de predicción de Extensiones de minería de datos (DMX) por medio del Generador de consultas de predicción en la ficha Predicción de modelo de minería de datos del Diseñador de minería de datos. El Generador de consultas de predicción es similar al Generador de consultas de Access; ofrece operaciones de arrastrar y colocar para crear las consultas. El Generador de consultas de predicción contiene las vistas siguientes:
- Diseño
- Consulta
- Resultado
Mediante las vistas Diseño y Consulta, puede crear y examinar una consulta. A continuación, puede ejecutar la consulta y ver los resultados en la vista Resultado.
Una vez que haya probado la precisión de los modelos de minería de datos y esté satisfecho con los resultados, puede crear consultas de predicción de Extensiones de minería de datos (DMX) por medio del Generador de consultas de predicción en la ficha Predicción de modelo de minería de datos del Diseñador de minería de datos. El Generador de consultas de predicción es similar al Generador de consultas de Access; ofrece operaciones de arrastrar y colocar para crear las consultas. El Generador de consultas de predicción contiene las vistas siguientes:
- Diseño
- Consulta
- Resultado
Mediante las vistas Diseño y Consulta, puede crear y examinar una consulta. A continuación, puede ejecutar la consulta y ver los resultados en la vista Resultado.

Crear la consulta
El primer paso para crear una consulta de predicción consiste en seleccionar una modelo de minería de datos y una tabla de entrada.
Para seleccionar un modelo de minería de datos y una tabla de entrada:
1. En la ficha Predicción de modelo de minería de datos del Diseñador de minería de datos, en el cuadro Modelo de minería de datos, haga clic en Seleccionar modelo.
Se abrirá el cuadro de diálogo Seleccionar modelo de minería de datos.
El primer paso para crear una consulta de predicción consiste en seleccionar una modelo de minería de datos y una tabla de entrada.
Para seleccionar un modelo de minería de datos y una tabla de entrada:
1. En la ficha Predicción de modelo de minería de datos del Diseñador de minería de datos, en el cuadro Modelo de minería de datos, haga clic en Seleccionar modelo.
Se abrirá el cuadro de diálogo Seleccionar modelo de minería de datos.
2. Desplácese por el árbol hasta la estructura Targeted Mailing, expándala, seleccione TM_Clustering y, a continuación, haga clic en Aceptar.

3. En el cuadro Seleccionar tabla(s) de entrada, haga clic en Seleccionar tabla de escenarios.
Se abrirá el cuadro de diálogo Seleccionar tabla.
4. En la lista Origen de datos, compruebe que Adventure Works DW se haya seleccionado.
5. En la lista Nombre de tabla o lista, seleccione la tabla ProspectiveBuyer y, a continuación, haga clic en Aceptar.
5. En la lista Nombre de tabla o lista, seleccione la tabla ProspectiveBuyer y, a continuación, haga clic en Aceptar.

Después de seleccionar la tabla de entrada, el Generador de consultas de predicción crea una asignación predeterminada entre el modelo de minería de datos y la tabla de entrada, en función de los nombres de las columnas.
Para crear una consulta de predicción:
Para crear una consulta de predicción:
1. En la columna Origen de la cuadrícula de la ficha Predicción de modelo de minería de datos, haga clic en la celda de la primera fila vacía y, a continuación, seleccione ProspectiveBuyer.
2. En la fila ProspectiveBuyer de la columna Campo, compruebe que ProspectBuyerKey se haya seleccionado.
De esta forma, se agregará un identificador único a la consulta de predicción para que pueda identificar quién es más y menos probable que compre una bicicleta, y quién es menos probable.
3. Haga clic en la siguiente fila vacía de la columna Origen y, a continuación, seleccione TM_Clustering.
4. En la fila TM_Clustering de la columna Campo, compruebe que Bike Buyer se haya seleccionado.
Esto determina que el modelo de árboles de decisión de Microsoft de la estructura de correo directo se utilice para crear predicciones.
5. Haga clic en la siguiente fila vacía de la columna Origen y, a continuación, seleccione Función de predicción.
6. En la fila Función de predicción, de la columna Campo, seleccione PredictProbability.
Las funciones de predicción proporcionan información acerca de cómo realiza las predicciones el modelo. La función PredictProbability proporciona información acerca de la corrección de la probabilidad de predicción. En la columna Criterios o argumento, puede especificar parámetros para la función de predicción.
7. En la fila PredictProbability de la columna Criterios o argumentos, escriba [TM_Clustering].[Bike Buyer].

De esta forma, se especificará la columna de destino para la función PredictProbability.
Haga clic en Cambiar a vista de resultado de consulta, que es el primer botón de la barra de herramientas de la ficha Predicción de modelo de minería de datos.
La tabla siguiente muestra una parte de los resultados que se devuelven. Estos resultados muestran que es probable que el cliente con Id. 7 compre una bicicleta, y la probabilidad de que la predicción sea correcta es del 66%.


Las columnas ProspectBuyerKey, BikeBuyer y Expression identifican a los clientes potenciales, indican si son compradores de bicicletas y la probabilidad de que la predicción sea correcta. Puede utilizar estos resultados para determinar a qué clientes potenciales debe dirigirse en el correo.
El primer botón en la barra de herramientas de la ficha Predicción de modelo de minería de datos le permite alternar entre tres vistas. Al hacer clic en Cambiar a vista de resultado de consulta, podrá ver los resultados de la consulta de predicción actual. Si está viendo los resultados, puede hacer clic en Cambiar a vista de diseño de consulta para volver a la cuadrícula y cambiar la consulta.
Si cambia a la vista Consulta, podrá ver y modificar el código DMX que creó el Generador de consultas de predicción. También puede ejecutar la consulta, modificarla y ejecutar la consulta modificada.
Por ejemplo, para ver sólo los clientes que es probable que compren una bicicleta y ordenarlos por orden descendente de probabilidad, puede agregar las instrucciones siguientes al final de la consulta DMX:
*Copiar código:
WHERE [Bike Buyer] = 1
ORDER BY PredictProbability([TM_Clustering].[Bike Buyer]) DESC
Puede alternar entre la vista Consulta y la vista Resultados; sin embargo, si vuelve a la vista Diseño, no se conservará la consulta modificada.
Bike Buyer ProspectiveBuyerKey Expression
*Copiar código:
WHERE [Bike Buyer] = 1
ORDER BY PredictProbability([TM_Clustering].[Bike Buyer]) DESC
Puede alternar entre la vista Consulta y la vista Resultados; sin embargo, si vuelve a la vista Diseño, no se conservará la consulta modificada.
Bike Buyer ProspectiveBuyerKey Expression
1 1718 0.68799600462319
1 1604 0.68799600462319
1 618 0.68786906979676
1 191 0.68786906979676
Ejercicio 6 Crear el escenario de cesta de previsión
Como analista de ventas de Adventure Works, se le ha solicitado una previsión de las ventas de modelos individuales de bicicletas para el próximo año. En concreto, debe obtener los picos en las ventas de bicicletas y determinar qué regiones lideran las ventas y cuáles van por detrás. Además, debe determinar si las ventas de diferentes modelos varían en función de la época del año.
Para hallar la información solicitada, en este ejercicio examinará los datos mensuales de la empresa y dividirá las ventas en tres regiones: Europa, Norteamérica y el Pacífico. Una vez que haya completado las tareas de este ejercicio, podrá responder a las preguntas siguientes:
- ¿En qué época del año se produce un pico en las ventas?
- ¿Cómo interactúan las ventas de los diferentes modelos de bicicleta a lo largo del año?
- ¿Existe un patrón de ventas para las tres regiones?
Para realizar las tareas de este ejercicio, utilizará el Algoritmo de serie temporal de Microsoft.
Crear una estructura del modelo de minería de datos Prevision
El primer paso para crear modelos de minería de datos para un escenario de previsión de ventas consiste en utilizar el Asistente para minería de datos y crear una estructura nueva de minería de datos. En esta tarea, utilizará el asistente para crear una estructura de minería de datos y el modelo inicial de minería de datos asociado. Ambos se basan en el algoritmo de serie temporal de Microsoft.
Para crear una estructura de minería de datos de previsión:
1. En el Explorador de soluciones de Business Intelligence Development Studio, haga clic con el botón secundario en Estructuras de minería de datos y seleccione Nueva estructura de minería de datos. Se abrirá el Asistente para minería de datos.
2. En la página de inicio del Asistente para minería de datos, haga clic en Siguiente.
3. En la página Seleccionar el método de definición, compruebe que la opción A partir de una base de datos relacional o un almacén de datos se ha seleccionado y, a continuación, haga clic en Siguiente.
3. En la página Seleccionar el método de definición, compruebe que la opción A partir de una base de datos relacional o un almacén de datos se ha seleccionado y, a continuación, haga clic en Siguiente.
4. En la página Seleccionar la técnica de minería de datos, en ¿Qué técnica de minería de datos desea utilizar?, seleccione Serie temporal de Microsoft y, a continuación, haga clic en Siguiente.

Aparecerá la página Seleccionar vista de origen de datos. De forma predeterminada, Adventure Works DW aparece seleccionada en Vistas de origen de datos disponibles.
5. Haga clic en Siguiente.
5. Haga clic en Siguiente.
6. En la página Especificar tipos de tablas, active la casilla de verificación Escenario, situada junto a la tabla vTimeSeries, y, a continuación, haga clic en Siguiente.

7. En la página Especificar los datos de entrenamiento, active las casillas de verificación Clave situadas junto a las columnas TimeIndex y ModelRegion.
8. Active las casillas de verificación Entrada y De predicción, situadas junto a la columna Quantity.
Esto indica que desea predecir esta columna.
9. Haga clic en Siguiente.
Esto indica que desea predecir esta columna.
9. Haga clic en Siguiente.

Aparecerá la página Especificar el contenido y el tipo de datos de las columnas.
La columna TimeIndex se designa automáticamente como una columna Key Time y la columna ModelRegion se designa como columna de clave. Esto significa que se creará un modelo de serie temporal separado por cada entrada única de la columna ModelRegion.
Los valores de la columna TimeIndex deben ser únicos entre los valores individuales de la columna ModelRegion.
10. Haga clic en Siguiente.
11. En la página Finalizando el asistente, en Nombre de la estructura de minería de datos, escriba Previsión.
12. En Nombre del modelo de minería de datos, escriba Previsión y, a continuación, haga clic en Finalizar.
El Diseñador de minería de datos se abre para mostrar la estructura de minería de datos Previsión que acaba de crear.

Modificar el modelo Previsión
La estructura de minería de datos que creó en la tarea anterior contiene un modelo de previsión individual. Antes de procesar y explorar el modelo, tiene que cambiar su estructura ligeramente y modificar una de sus propiedades.
Modificar la estructura de minería de datos
Puede modificar la estructura de minería de datos utilizando la ficha Estructura de minería de datos del Diseñador de minería de datos.
La estructura de minería de datos que creó en la tarea anterior contiene un modelo de previsión individual. Antes de procesar y explorar el modelo, tiene que cambiar su estructura ligeramente y modificar una de sus propiedades.
Modificar la estructura de minería de datos
Puede modificar la estructura de minería de datos utilizando la ficha Estructura de minería de datos del Diseñador de minería de datos.
Cuando creó el modelo con el Asistente para minería de datos, utilizó tres columnas: TimeIndex, ModelRegion y Quantity.
La tabla Prevision también contiene una columna Amount, que puede utilizar para calcular el importe de las ventas. Mediante la ficha Estructura de minería de datos, puede agregar esta columna desde la vista de origen de datos a la estructura de minería de datos.
Para agregar la columna Amount a la estructura de minería de datos Prevision:
1. En la ficha Estructura de minería de datos del Diseñador de minería de datos, ubicada en el panel Vista de origen de datos, seleccione la columna Amount en la tabla vTimeSeries.
2. Arrastre la columna Amount desde el panel Vista de origen de datos hasta la lista de columnas de la estructura Prevision.

Para agregar la columna Amount a la estructura de minería de datos Prevision:
1. En la ficha Estructura de minería de datos del Diseñador de minería de datos, ubicada en el panel Vista de origen de datos, seleccione la columna Amount en la tabla vTimeSeries.
2. Arrastre la columna Amount desde el panel Vista de origen de datos hasta la lista de columnas de la estructura Prevision.


La columna Amount ahora forma parte de la estructura de minería de datos Prevision.
Modificar el modelo de minería de datos
Dado que ha agregado una columna nueva a la estructura, debe definir la forma en que el modelo utilizará la columna. Puede especificar cómo se utilizará la columna en la ficha Modelos de minería de datos del Diseñador de minería de datos.
Dado que ha agregado una columna nueva a la estructura, debe definir la forma en que el modelo utilizará la columna. Puede especificar cómo se utilizará la columna en la ficha Modelos de minería de datos del Diseñador de minería de datos.
La ficha Modelos de minería de datos enumera las columnas que la estructura de minería de datos contiene en la columna Structure de la cuadrícula, así como las columnas que el modelo contiene en una columna que tiene el nombre del modelo, en este caso Prevision. Haga clic en los nombres de las columnas o el nombre del modelo para hacer modificaciones.
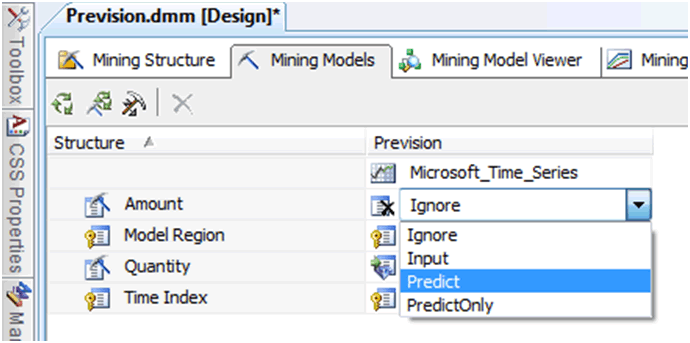
Para definir cómo se utilizará la columna Amount
1. En la columna Prevision de la cuadrícula de la ficha Modelos de minería de datos, haga clic en la celda correspondiente a la fila Amount. Aparecerá una lista que contiene las opciones Ignore, Input, Predict y PredictOnly.
2. Seleccione Predict.
La columna Amount es ahora una columna de entrada y una columna de predicción. También puede cambiar las propiedades de columnas individuales seleccionando la columna y abriendo la ventana Propiedades. Para abrir la ventana Propiedades, haga clic con el botón secundario en el nombre de la columna y, a continuación, seleccione Propiedades. Si cambia una propiedad de la columna para un modelo individual, sólo podrá cambiar las propiedades para ese modelo. No obstante, si cambia una propiedad dentro de la columna Structure, el cambio afectará a todos los modelos asociados a la estructura.
Si selecciona la columna Prevision, puede cambiar las propiedades y parámetros asociados al modelo. El algoritmo de series temporales de Microsoft contiene varios parámetros que afectan al modo de creación de un modelo.
En este ejercicio, tendrá que ajustar el valor del parámetro PERIODICITY_HINT para el modelo Prevision. Este parámetro proporciona al algoritmo información sobre la frecuencia de repetición de los datos. El patrón de datos de AdventureWorks DW se extrae mensualmente; la periodicidad es anual.
Por tanto, establezca el parámetro PERIODICITY_HINT en 12 para indicar que un patrón se repite cada año.
Para cambiar el parámetro PERIODICITY_HINT:
1. En la ficha Modelos de minería de datos, haga clic con el botón secundario en Prevision y seleccione Establecer parámetros de algoritmo. Se abrirá la ventana Parámetros de algoritmo.
1. En la ficha Modelos de minería de datos, haga clic con el botón secundario en Prevision y seleccione Establecer parámetros de algoritmo. Se abrirá la ventana Parámetros de algoritmo.

2. En la columna Valor, establezca PERIODICITY_HINT en {12} y, a continuación, haga clic en Aceptar.

Procesar el modelo de minería de datos
Ahora que la estructura y los parámetros para el modelo de minería de datos se han completado, puede procesar el modelo.
Para procesar el modelo de minería de datos:
1. En el menú Modelo de minería de datos de BI Development Studio, seleccione Procesar estructura de minería de datos y todos los modelos.
Se abre el cuadro de diálogo Procesar estructura de minería de datos: Previsión.
2. Haga clic en Ejecutar.
Se abre el cuadro de diálogo Progreso del proceso para mostrar información acerca del procesamiento del modelo. El procesamiento del modelo puede llevar algún tiempo, dependiendo del equipo.
3. Una vez que el procesamiento se haya completado, haga clic en Cerrar en los cuadros de diálogo Progreso del proceso y Procesar estructura de minería de datos: Prevision.


Explorar el modelo Prevision
Después de crear el modelo de previsión, puede explorar los resultados utilizando el Visor de series temporales de Microsoft, que se encuentra en la ficha Visor de modelos de minería de datos del Diseñador de minería de datos. El Visor de series temporales de Microsoft contiene dos fichas: Árbol de decisión y Gráficos.
Después de crear el modelo de previsión, puede explorar los resultados utilizando el Visor de series temporales de Microsoft, que se encuentra en la ficha Visor de modelos de minería de datos del Diseñador de minería de datos. El Visor de series temporales de Microsoft contiene dos fichas: Árbol de decisión y Gráficos.
El algoritmo de serie temporal de Microsoft crea un modelo por cada serie diferente que exista en el conjunto de datos. Por ejemplo, cada región del conjunto de datos incluye datos acerca de las ventas relativas a un período de tiempo; por tanto, el algoritmo crea una serie temporal independiente para cada región. Cada serie temporal incluye información sobre la cantidad de ventas y el importe de ventas.
En esta tarea, explorará la serie temporal que describe las ventas en las regiones de Europa, Norteamérica y el Pacífico.
Ficha Árbol de decisión
La ficha Árbol de decisión del Visor de series temporales de Microsoft del Diseñador de minería de datos le permite ver el árbol de decisión que se creó al procesar el modelo.
Para ver el árbol de decisión
1. En la lista Árbol de la ficha Árbol de decisión del visor, seleccione el modelo M200 Pacific: Amount.
Cada uno de los nodos de un árbol de decisión muestra tres extractos de información:
- La concentración de escenarios para el estado del atributo de predicción que se ha especificado en el control Fondo. Tanto la ventana Leyenda de minería de datos como el recuadro informativo que aparece al detener el puntero sobre un objeto del árbol proporcionan el número exacto de escenarios.
- La fórmula de regresión para el nodo.
- Un gráfico de rombo que representa el intervalo del atributo. El rombo está ubicado en la media del nodo y el ancho del rombo representa la varianza del atributo en el nodo. Un rombo más estrecho indica que el nodo puede crear una predicción de mayor calidad.


Ficha Gráficos
Mediante la ficha Gráficos del Visor de series temporales de Microsoft, puede examinar las series temporales creadas por el algoritmo.
Para seleccionar una serie temporal
1. Cambie a la ficha Gráficos de la ficha Visor de modelos de minería de datos.
2. En el cuadro de lista desplegable situado a la derecha de la vista del gráfico,
seleccione las casillas de verificación de las series temporales siguientes:
- R750 Europe:Amount
- R750 North America:Amount
- R750 Pacific:Amount
3. Haga clic en Aceptar.
La leyenda de la parte derecha del visor enumera las series seleccionadas en el cuadro de lista desplegable e incluye una casilla de verificación para cada serie. Mediante la activación y desactivación de las casillas de verificación de la leyenda, puede controlar las series temporales que aparecen en el visor.
El gráfico muestra datos históricos y futuros. Los datos futuros aparecen sombreados para diferenciarse de los históricos. Utilice la lista Pasos de predicción para controlar cuántos pasos futuros de datos se mostrarán. Utilice la casilla de verificación Mostrar desviaciones para agregar barras de error a las predicciones.
Como puede ver en el visor, las ventas totales de todas las regiones se incrementan
generalmente en diciembre, con un pico cada 12 meses. Las predicciones continúan esta tendencia.

Ejercicio 7: Crear el escenario de cesta de mercado
El departamento de marketing de Adventure Works desea mejorar el sitio Web de la empresa para promover las ventas cruzadas.
Antes de actualizar el sitio, necesitan crear un modelo de minería de datos que pueda predecir los productos cuya adquisición podría interesar a los clientes, basándose en otros productos que ya se encuentran en las cestas de la compra en línea de los clientes. Estas predicciones también ayudarán al departamento de marketing a agrupar en el sitio Web aquellos artículos que los clientes suelen comprar juntos. Una vez que haya completado este ejercicio, obtendrá un modelo de minería de datos con el que podrá predecir artículos adicionales que pueden aparecer en una cesta de la compra o que un cliente podría querer agregar a la cesta de la compra. Asimismo, contará con un completo modelo de minería de datos que muestra grupos de artículos de transacciones históricas del cliente.
Crear una estructura del modelo de minería de datos Market Basket
El primer paso para crear un escenario de cesta de mercado consiste en utilizar el Asistente para minería de datos con el fin de crear una estructura nueva de minería de datos. En esta tarea, utilizará el asistente para crear una estructura de minería de datos y el modelo inicial de minería de datos asociado. Ambos se basan en el algoritmo de asociación de Microsoft.
Para crear una estructura de minería de datos de asociación
1. En el Explorador de soluciones de Business Intelligence Development Studio, haga
clic con el botón secundario en Estructuras de minería de datos y seleccione Nueva estructura de minería de datos. Se abrirá el Asistente para minería de datos.
2. En la página de inicio del Asistente para minería de datos, haga clic en Siguiente.
3. En la página Seleccionar el método de definición, compruebe que la opción A partir de una base de datos relacional o un almacén de datos se ha seleccionado y, a continuación, haga clic en Siguiente.
4. En la página Seleccionar la técnica de minería de datos, en ¿Qué técnica de minería de datos desea utilizar?, seleccione Reglas de asociación de Microsoft y, a continuación, haga clic en Siguiente. Aparecerá la página Seleccionar vista de origen de datos. De forma predeterminada, Adventure Works DW aparece seleccionada en Vistas de origen de datos disponibles.
El primer paso para crear un escenario de cesta de mercado consiste en utilizar el Asistente para minería de datos con el fin de crear una estructura nueva de minería de datos. En esta tarea, utilizará el asistente para crear una estructura de minería de datos y el modelo inicial de minería de datos asociado. Ambos se basan en el algoritmo de asociación de Microsoft.
Para crear una estructura de minería de datos de asociación
1. En el Explorador de soluciones de Business Intelligence Development Studio, haga
clic con el botón secundario en Estructuras de minería de datos y seleccione Nueva estructura de minería de datos. Se abrirá el Asistente para minería de datos.
2. En la página de inicio del Asistente para minería de datos, haga clic en Siguiente.
3. En la página Seleccionar el método de definición, compruebe que la opción A partir de una base de datos relacional o un almacén de datos se ha seleccionado y, a continuación, haga clic en Siguiente.
4. En la página Seleccionar la técnica de minería de datos, en ¿Qué técnica de minería de datos desea utilizar?, seleccione Reglas de asociación de Microsoft y, a continuación, haga clic en Siguiente. Aparecerá la página Seleccionar vista de origen de datos. De forma predeterminada, Adventure Works DW aparece seleccionada en Vistas de origen de datos disponibles.

5. Haga clic en Siguiente.
6. En la página Especificar tipos de tablas, active la casilla de verificación Escenario, situada junto a la tabla vAssocSeqOrders, y la casilla de verificación Anidado, situada junto a la tabla vAssocSeqLineItems; a continuación, haga clic
en Siguiente.

7. En la página Especificar los datos de entrenamiento, desactive la casilla de verificación Clave, situada junto a CustomerKey, y las casillas Clave y Entrada, situadas junto a LineNumber.

8. Active las casillas de verificación Clave y De predicción, situadas junto a la columna Model. La casilla Entrada se selecciona automáticamente.
9. Haga clic en Siguiente.
10. En la página Especificar el contenido y el tipo de datos de las columnas, haga clic en Siguiente.
11. En la página Finalizando el asistente, en Nombre de la estructura de minería de datos, escriba Association.
12. En Nombre del modelo de minería de datos, escriba Association y, a continuación, haga clic en Finalizar.
El Diseñador de minería de datos se abre para mostrar la estructura de minería de datos Association que acaba de crear.
9. Haga clic en Siguiente.
10. En la página Especificar el contenido y el tipo de datos de las columnas, haga clic en Siguiente.
11. En la página Finalizando el asistente, en Nombre de la estructura de minería de datos, escriba Association.
12. En Nombre del modelo de minería de datos, escriba Association y, a continuación, haga clic en Finalizar.
El Diseñador de minería de datos se abre para mostrar la estructura de minería de datos Association que acaba de crear.

Modificar el modelo Market Basket
Antes de procesar el modelo de minería de datos inicial que creó junto con la estructura de minería de datos Association en la tarea anterior, debe cambiar los valores predeterminados de dos de los parámetros: Support y Probability. Support define el porcentaje de escenarios en los que una regla debe existir antes de que se considere válida. Probability define la probabilidad de que una asociación se considere válida.
Para ajustar los parámetros del modelo Association
1. Abra la ficha Modelos de minería de datos del Diseñador de minería de datos.
2. Haga clic con el botón secundario en la columna Association de la cuadrícula del diseñador y seleccione Establecer parámetros de algoritmo. Se abrirá la ventana Parámetros de algoritmo.
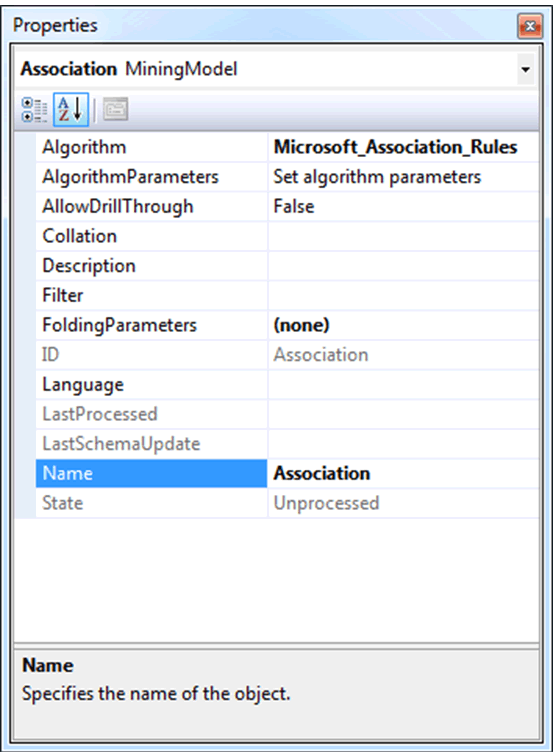
3. En la columna Valor del cuadro de diálogo Parámetros de algoritmo, establezca los parámetros siguientes:
MINIMUM_PROBABILITY = 0.1
MINIMUM_SUPPORT = 0.01
4. Haga clic en Aceptar.

Procesar el modelo de minería de datos
Ahora que ha definido la estructura y los parámetros para el modelo de minería de datos Association, puede procesar el modelo.
Explorar los modelos Market Basket
Después de crear el modelo Association, puede explorarlo con el visor de asociación de Microsoft, que se encuentra en la ficha Visor de modelos de minería de datos del Diseñador de minería de datos. Al explorar el modelo, podrá ver fácilmente los productos que tienden a aparecer juntos y explorar las relaciones entre los elementos. También puede filtrar las asociaciones más débiles y obtener una idea general de los patrones emergentes.
El visor de asociación de Microsoft contiene tres fichas: Conjuntos de elementos, Reglas y Red de dependencias.
Ficha Conjuntos de elementos
La ficha Conjuntos de elementos muestra tres extractos de información importantes que se relacionan con los conjuntos de elementos que el algoritmo de asociación de Microsoft detecta: el soporte, que es el número de transacciones en las que tiene lugar el conjunto de elementos; el tamaño, que es el número de elementos incluidos en el conjunto; y la composición real del conjunto de elementos. Dependiendo de cómo se configuren los parámetros del algoritmo, éste puede generar un número elevado de conjuntos de elementos. Mediante los controles situados en la parte superior de la ficha Conjuntos de elementos, puede filtrar el visor para que muestre sólo los conjuntos de elementos que tengan un tamaño y un soporte mínimo especificos.
También puede utilizar el cuadro Filtrar conjunto de elementos para filtrar conjuntos de elementos mostrados en el visor. Por ejemplo, para ver sólo los conjuntos de elementos que contienen información acerca de la bicicleta Mountain-200, escriba Mountain-200 en Filtrar conjunto de elementos. Como podrá ver en el visor, sólo se muestran los conjuntos de elementos que contienen la palabra "Mountain-200". Todos los conjuntos de elementos que muestra el visor contienen información sobre las transacciones en las que se vendió una bicicleta Mountain-200. Por ejemplo, el conjunto de elementos que contiene el valor 511 en la columna Soporte indica que, de todas las transacciones, 511 personas que compraron la bicicleta Mountain-200 también compraron el modelo Sport-100.

Ficha Reglas
La ficha Reglas muestra la siguiente información relacionada con las reglas que el algoritmo encuentra.
-Probabilidad
Posibilidad de que se produzca una regla.
- Importancia
Mide la utilidad de una regla; un valor elevado significa que la regla es mejor.
Guiarse sólo por la probabilidad puede conducir a error. Por ejemplo, si todas las transacciones contienen un elemento x, la regla y predice que x tiene una probabilidad de 1, lo que quiere decir que x siempre ocurrirá. Aunque la precisión de la regla es muy buena, no transmite mucha información porque cada transacción contiene x con independencia de y.
- Regla
Definición de la regla.
Al igual que con la ficha Conjuntos de datos, puede filtrar las reglas para mostrar sólo las más interesantes. Por ejemplo, si desea ver sólo las reglas que incluyen la bicicleta Mountain-200, escriba Mountain-200 en el cuadro Regla del filtro. A continuación, el visor mostrará sólo las reglas que contengan la palabra "Mountain-200". Cada regla puede utilizarse para predecir la presencia de un elemento de una transacción en función de la presencia de otros elementos. Por ejemplo, la primera regla le dice que cuando alguien compra una bicicleta Mountain-200 y una botella de agua, hay una probabilidad de 1 de que esta persona compre también un soporte para botellas Mountain.

Ficha Red de dependencias
Mediante la ficha Red de dependencias, puede examinar la interacción entre los diferentes elementos del modelo. Cada nodo del visor representa un elemento; por ejemplo, el nodo Mountain-200 = Existing indica que Mountain-200 existe en una transacción. Al seleccionar un nodo, puede utilizar la leyenda de color de la parte inferior de la ficha para establecer los elementos que determinan o son determinados por otros elementos del modelo.
El control deslizante está asociado con la probabilidad de una regla. Muévalo arriba o abajo para filtrar las asociaciones débiles. Por ejemplo, en el cuadro Mostrar, seleccione Mostrar sólo el nombre del atributo y, a continuación, haga clic en el nodo Mountain Bottle Cage. El visor muestra que el soporte para botellas Mountain (Mountain Bottle Cage) predice y, a su vez, es predicho por la botella de agua y la bicicleta Mountain-200.
Esto significa que estos elementos aparecerán probablemente juntos en una transacción. En otras palabras, si un cliente compra una bicicleta, es probable que también compre una botella de agua y un soporte para botellas de agua.

Ver mas informacion en video disponible en este blog.